Federation Over Embeddings: Let AI Agents Query Data Where It Lives
Someone told you to pivot to AI. Add an AI layer. “We need to be AI-first.”
Fair enough. So you start thinking: what does AI need? Data. Obviously.
So the playbook writes itself: collect data in a central place, set up a vector database, do some chunking, build a RAG pipeline, maybe fine-tune a model. Then query it. Ship the chatbot. Declare victory.
This is what I call the AI centralization tax. Not the cost of having a data warehouse, that’s often justified. The tax is building a parallel AI-specific data infrastructure on top of what you already have: vector databases, embedding pipelines, chunking strategies, custom models. A whole new layer, just for AI.
Here’s the thing: you might eventually need some of that. But probably not yet. And probably not for the use cases you think.
You likely already have systems that hold your data: CRMs, support platforms, billing systems, maybe a data warehouse. The question isn’t whether to centralize data (you probably already have). The question is whether AI needs its own separate copy, transformed into embeddings, stored in yet another database.
The answer is almost always no.
If you’re going after differentiation, if you’re trying to prove unit economics, if you’re racing to stay ahead of competitors, building AI-specific infrastructure before seeing any returns is a strategic mistake. You’re creating a parallel data estate for questions you haven’t validated.
And here’s the trap: once you’ve invested months building embedding pipelines and vector infrastructure, it’s painful to pivot even when better options emerge. That’s not just technical debt. That’s strategic lock-in to an architecture that may already be obsolete.
Let’s Be Blunt
Someone asks: “What’s the health of this customer?”
You don’t need a RAG pipeline for that. You don’t need a vector database. You don’t need your own model. You don’t need a data warehouse with months of ETL work.
What you need: an AI agent with tool calling capabilities and a capable foundation model. That’s it. Everything else is optimization.
An agentic AI system with tool access can query your CRM, pull recent support tickets, check billing status, and synthesize a health assessment in seconds, with real-time data, without any infrastructure you need to build or maintain.
This isn’t theoretical. This is what’s possible right now with MCP (Model Context Protocol) and Agent orchestration frameworks.
If your AI use case looks anything like “get me information about X from our systems,” stop. Don’t reach for the centralization playbook. There’s a faster path.
The AI Centralization Playbook
Four approaches, same trap: building AI-specific infrastructure instead of leveraging what you have:
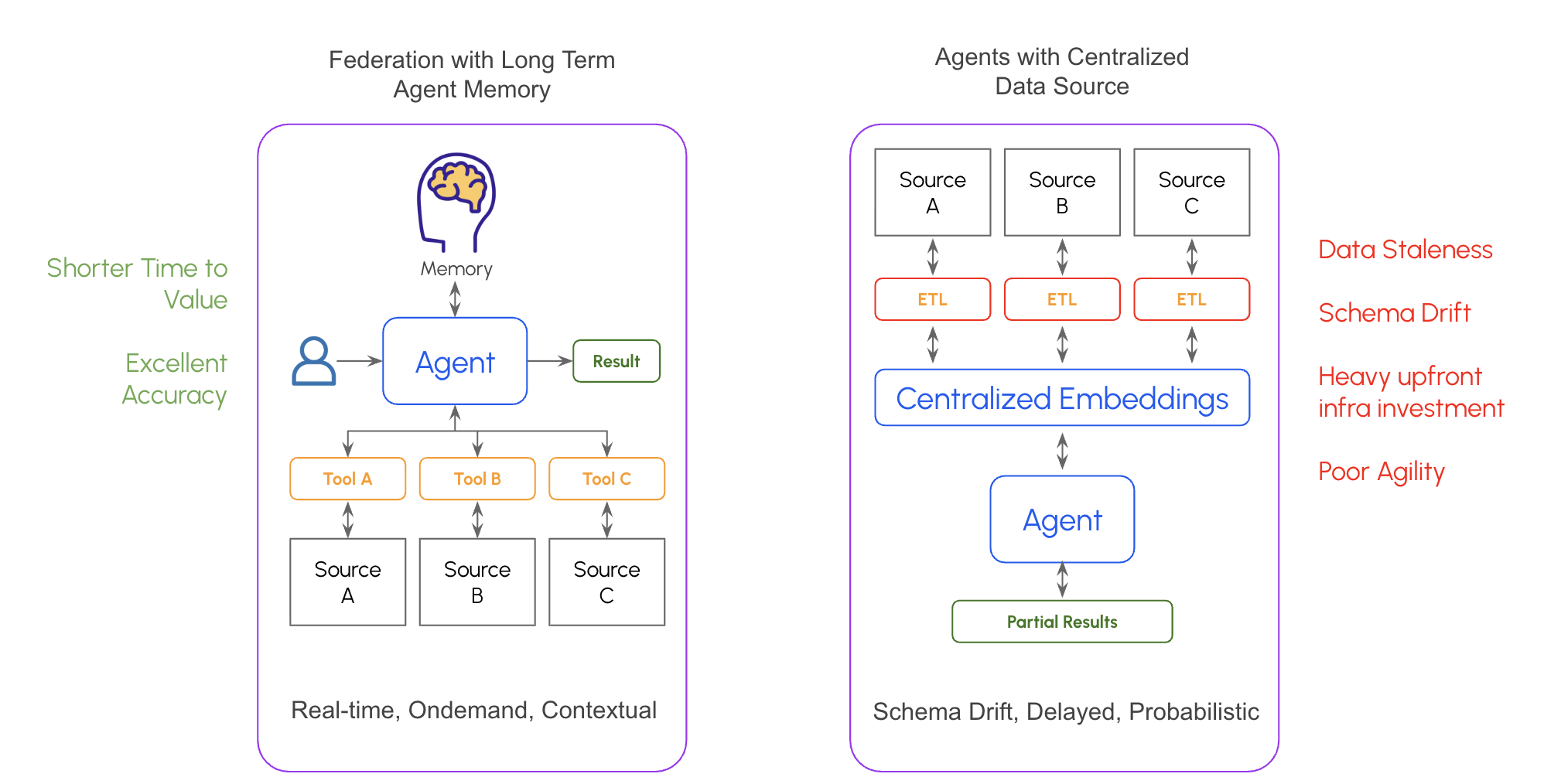
RAG pipelines. Chunk your documents, generate embeddings, store them in a vector database, retrieve the top-k matches, stuff them into context. Works for “chat with your PDF.” Falls apart when you need accurate structured results, ask for a count or an aggregation and you get hallucinated numbers. Teams keep optimizing chunking strategies and similarity thresholds, solving the wrong problem.Custom fine-tuned models. Collect training data, curate examples, run fine-tuning jobs, deploy, monitor drift. Weeks or months of work. By the time you ship, base models have improved and your fine-tune is already behind.Data warehouses for AI. You already have Snowflake or BigQuery for analytics. The AI playbook says: now build semantic layers, create AI-specific transformations, maybe replicate into a vector store. More infrastructure, more maintenance, when an AI agent could just query your existing warehouse directly via tool calling.Knowledge graphs for AI. Model your domain as entities and relationships, ingest data, build traversal logic. Months of work, brittle when schemas change, solving a problem that agentic systems with tools can often handle through reasoning.
Same pattern: assume AI needs its own data layer. Same problem: you’re building parallel infrastructure instead of connecting to what exists.
Federation: The RAG Alternative That Ships
There’s a simpler question: why does AI need its own copy of the data?
If AI agents can reason, and tools can query systems, and LLMs can synthesize, the data can stay where it already lives.Query at runtime. Synthesize on demand.
That’s federation. Instead of copying data into AI-specific infrastructure, give agents tools to query your existing systems directly.
Critical clarification: A Snowflake warehouse with an MCP server is federation. You’re querying data where it lives. The warehouse serves its purpose, and AI agents access it directly without needing a vector layer on top. Federation isn’t anti-warehouse, it’s anti-duplication.What makes this viable now: Model capability. Frontier LLMs handle multi-step reasoning and tool orchestration reliably. Context windows hold results from multiple system queries. The models do synthesis that would have required custom code two years ago.Tool standardization via MCP. The Model Context Protocol has emerged as the standard for connecting AI agents to external systems. Major model providers: Anthropic, OpenAI have adopted it. The ecosystem now includes thousands of pre-built integrations: CRMs, support systems, billing platforms, databases, developer tools. And there are MCP runtimes that handle authorization at query time, agents authenticate as the user rather than relying on over-privileged service accounts.Agent frameworks. The orchestration layer has matured. Chain-of-thought reasoning means agents recover from mistakes and converge on correct answers. Error handling that required explicit coding is now emergent behavior.
Three AI Agent Architecture Patterns
Each pattern builds on the previous one. Start simple, add complexity only when you hit limits.
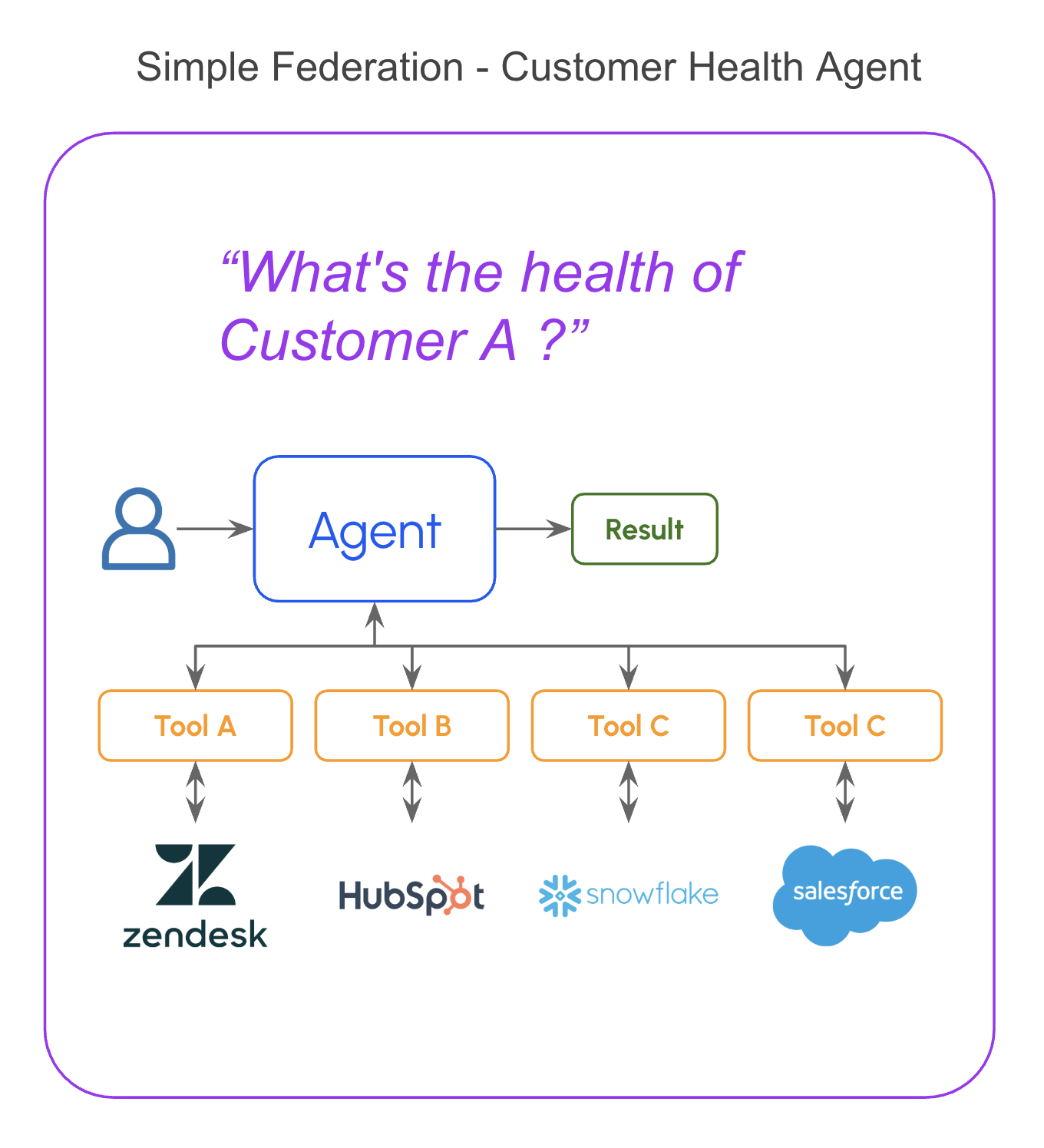
Pattern 1: Simple Federation with Tool Calling
The foundational pattern. An AI agent receives a query, uses tool calling to query source systems via MCP servers, and synthesizes the answer.
Don’t underestimate this. With current LLMs, simple federation handles most “get me information about X” queries, status checks, lookups, cross-system research without any custom infrastructure.
The key insight: the agent is the join layer. It reasons across sources, handles schema differences through semantic understanding, and synthesizes coherent answers. You don’t need to model the relationships in advance, the agent figures them out at query time.
 How it works: The agent maintains minimal state, just enough to track the conversation and coordinate MCP tool calls. Each query hits source systems directly, gets fresh data, returns results. Agent frameworks like LangGraph provide state persistence and checkpointing out of the box, this alone takes you a long way.Works for: Status checks, lookups, cross-system queries, research tasks. “What’s the health of Acme Corp?” “Show me recent tickets for this customer.” “What’s our pipeline this quarter?” “Compare this customer’s support history with their billing status.”Limitations: Adds latency (typically 2-5 seconds for multi-system queries, on top of model inference time). No persistent memory across sessions, as more tools and systems are queried within a session, context grows and accuracy can degrade.When it breaks: Queries requiring computation across large datasets (aggregations over thousands of records), sub-second response requirements, or queries where source API latency compounds unacceptably.
How it works: The agent maintains minimal state, just enough to track the conversation and coordinate MCP tool calls. Each query hits source systems directly, gets fresh data, returns results. Agent frameworks like LangGraph provide state persistence and checkpointing out of the box, this alone takes you a long way.Works for: Status checks, lookups, cross-system queries, research tasks. “What’s the health of Acme Corp?” “Show me recent tickets for this customer.” “What’s our pipeline this quarter?” “Compare this customer’s support history with their billing status.”Limitations: Adds latency (typically 2-5 seconds for multi-system queries, on top of model inference time). No persistent memory across sessions, as more tools and systems are queried within a session, context grows and accuracy can degrade.When it breaks: Queries requiring computation across large datasets (aggregations over thousands of records), sub-second response requirements, or queries where source API latency compounds unacceptably.
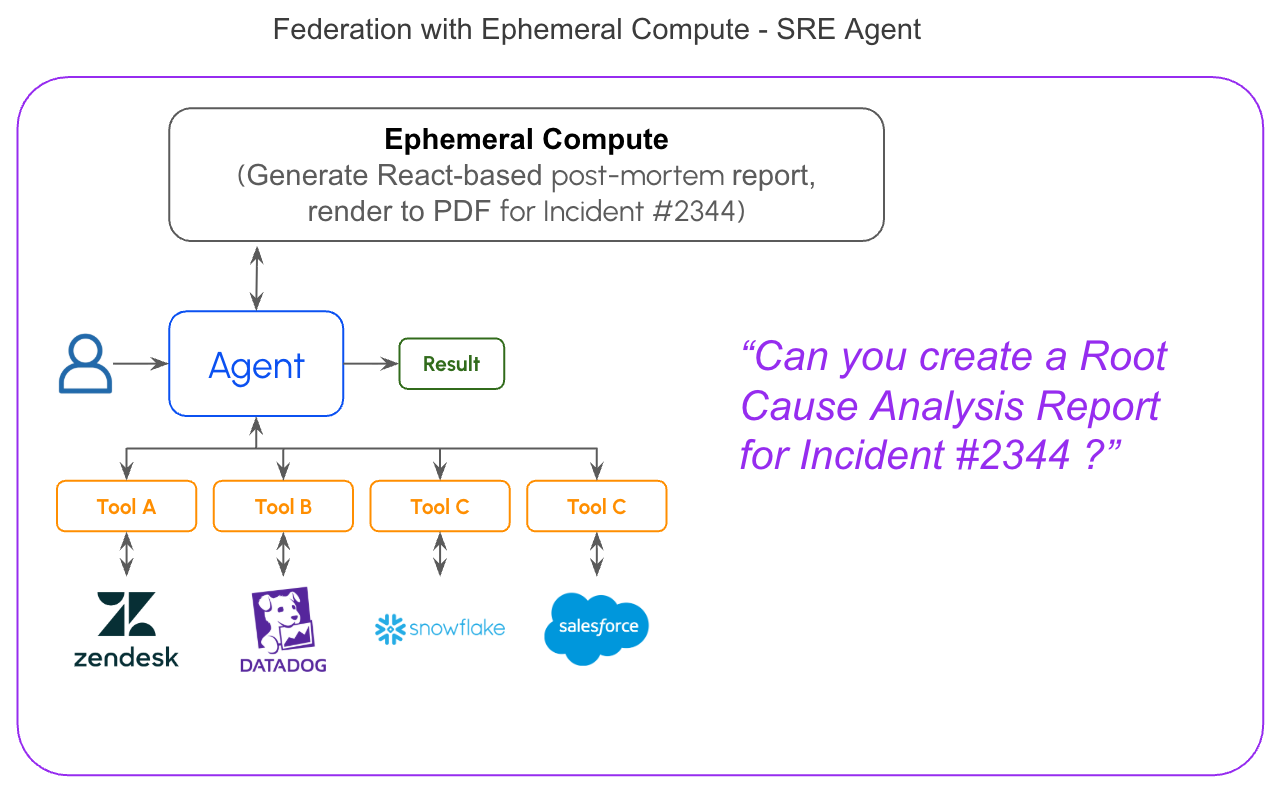
Pattern 2: Federation with Ephemeral Compute
Simple federation handles most queries. But some tasks need more: complex aggregations, data transformations, joins across large result sets, or generating artifacts from fetched data.
For these cases, add ephemeral compute.
 How it works: The AI agent fetches data via MCP tools, then spins up temporary compute, a sandboxed environment where it can execute code, run SQL against in-memory databases, or process data programmatically. Results return, compute disposes. Sandboxed environments like E2B are built specifically for this pattern.Works for: Cross-system joins over thousands of records, complex aggregations, code generation from data, document assembly, analytical scripts.Limitations: More complex orchestration. Adds latency (compute spin-up plus execution time). The join logic itself can be complex when schemas don’t align, you’re writing fuzzy matching or asking the agent to reason about entity resolution.When it breaks: Datasets exceeding what fits in memory (typically 100K+ records depending on schema width), queries requiring historical data the source systems don’t retain, or when you need results cached for repeated access.
How it works: The AI agent fetches data via MCP tools, then spins up temporary compute, a sandboxed environment where it can execute code, run SQL against in-memory databases, or process data programmatically. Results return, compute disposes. Sandboxed environments like E2B are built specifically for this pattern.Works for: Cross-system joins over thousands of records, complex aggregations, code generation from data, document assembly, analytical scripts.Limitations: More complex orchestration. Adds latency (compute spin-up plus execution time). The join logic itself can be complex when schemas don’t align, you’re writing fuzzy matching or asking the agent to reason about entity resolution.When it breaks: Datasets exceeding what fits in memory (typically 100K+ records depending on schema width), queries requiring historical data the source systems don’t retain, or when you need results cached for repeated access.
Pattern 3: Agentic AI with Long-term Memory
Add persistent context that accumulates across sessions. The AI agent federates for current data but also maintains memory of decisions, context, and precedents.
 How it works: Before querying live systems, the agent checks memory for relevant history. This isn’t about embedding your entire data estate, it’s about persisting agent-generated context: decisions made, precedents set, user preferences learned. Memory layers like Mem0 and Zep are emerging to solve this.
How it works: Before querying live systems, the agent checks memory for relevant history. This isn’t about embedding your entire data estate, it’s about persisting agent-generated context: decisions made, precedents set, user preferences learned. Memory layers like Mem0 and Zep are emerging to solve this.
The difference from traditional RAG: You’re storing agent-generated context, not raw source documents. It’s accumulated intelligence from interactions, not replicated data. The memory is append-only and grows organically from actual usage.Works for: Decision support with precedent (”Should we approve this discount? What did we do for similar deals?”), personalized experiences that improve over time, audit trails of agent reasoning.Limitations: Memory architecture is still maturing across the ecosystem. You need explicit decisions about what’s worth persisting. Memory retrieval adds latency and can surface irrelevant context.
What About the Edge Cases?“What about schema mismatches?” When Salesforce’s “Account” doesn’t match Stripe’s “Customer” that’s a SQL problem, not a vector problem. An AI agent with schema context can write joins that handle naming conventions and fuzzy matching. You need a capable model and well-designed MCP tools, not embeddings.“What about finding similar customers?” Before reaching for vector similarity, ask: can SQL pattern matching, joins, and filtering get you there? Most “similarity” use cases are structural, not semantic. Agent reasoning with tools can get you there.“What about latency and API costs?” Yes, LLM inference costs money. Compare that to three months of infrastructure investment before you’ve validated whether the use case matters. The model cost is the cheaper way to learn.When you genuinely need vector search: Semantic search over large unstructured document sets where keyword search fails. That’s RAG’s sweet spot. Build it as an isolated tool: a vector store exposed via MCP, not as a centralized AI data layer.
The pattern:solve isolated problems with isolated tools.
The Asymmetry That Matters
You might eventually need a vector store for semantic search over documents. You might need a fine-tuned model for domain-specific language. You might need embeddings for true similarity matching at scale.
But you don’t have to build any of that to start delivering value.
That’s the asymmetry. You can always add AI-specific infrastructure later: vector stores, custom models, embedding pipelines for the isolated use cases that genuinely require them. The tools-first architecture accommodates it. Build the vector store when you’ve proven you need semantic search. Fine-tune a model when base models demonstrably fall short.
You cannot easily do the reverse. Once you’ve invested months in embedding pipelines and vector infrastructure, you have teams maintaining them and stakeholders defending the investment. Pivoting to simpler tool-based approaches means stranded infrastructure and difficult conversations about sunk costs.
Start with MCP tools. Ship value in days. Add complexity only where it’s earned.
If you start with the AI centralization playbook? By the time you’ve built the embedding pipelines and shipped the vector infrastructure, competitors who started with tools are on their third iteration. They’ve validated what users actually want. They’re capturing market share while you’re debugging retrieval accuracy.
The Bottom Line
Your data already lives somewhere: CRMs, support platforms, billing systems, data warehouses. AI agents with MCP tools can query those systems directly and synthesize answers in seconds.
Schema mismatches? An agent with context can reason through them. Cross-system joins? Ephemeral compute. Similarity search? Often just SQL pattern matching. Semantic search over unstructured documents? That’s where a vector store earns its place: as one MCP tool among many, not as the foundation of your architecture.
The pattern I keep seeing work: start with federation, ship value quickly, then add specialized infrastructure only for the specific problems that genuinely require it. Vector stores, custom models, embedding pipelines, they all have their place. But that place is usually narrower than the default playbook suggests.
Most enterprise AI use cases are variations of “get me information about X from our systems.” For that, agents and tools are enough. The organizations shipping fastest have figured this out.
Query data where it lives. Add complexity only where it’s earned.